
Overview
The goal of this project is to predict robot motion by monitoring human motion using a cross-domain multimodal variational autoencoder (mVAE) model. The human motion contains two type of electronic signal: electromyography (EMG) and inertial measurement unit (IMU), collecting by Myo arm band. The robot motion contains the positions and velocities of 7 joints of Franka pandas arm, collecting by the simulation in ROS MoveIt. This project applies signal processing and data augmentation on the acquisited huamn/robot data to build the dataset. The mVAE model is adapted from the paper Multimodal representation models for prediction and control from partial information[1].
pipeline
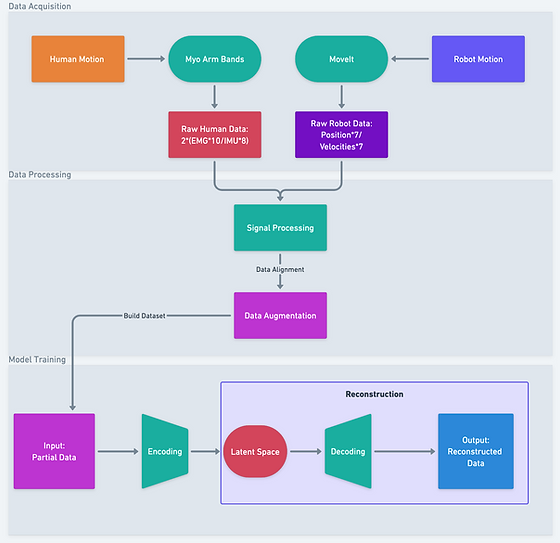
Data Acquisition
-
Design Task:
-
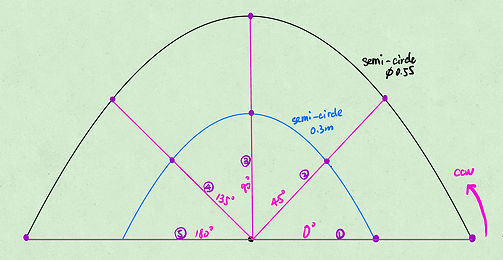
Collecting data from both end during performing 5 task with different angle, each task contains 4 segments:
-
from home to reach the object at degree of 0, 45, 90, 135, 180 (CCW) with radius of 0.3m
-
pick the object straight up
-
move the object radially away with radius of 0.55m
-
back to home position
-
-
The following picture demonstrates the geometric plane for 5 tasks:
-
-
Each task will have 10 repeats, Below is the demo for performing single repeat of task 2, and experimenter should wear Myos as right picture shows:

-
Raw Human Data
-
Electromyography (EMG): 8 channels measuring muscle response or electrical activity in response to a nerve's stimulation of the muscle at 200 Hz for both forearm and upper arm
-
Inertial measurement unit (IMU): 10 channels measuring angular rate and linear acceleration at 50Hz for both forearm and upper arm
-
Below first demo is collected from forearm, second from upper arm. For each demo: the left upper one is 3 channel IMU linear acceleration, upper right one is 3 channel angular velocity, the bottom left one is 4 channel IMU orientation represented in quaternion, the bottom right one is 8 channel EMG data
-
-
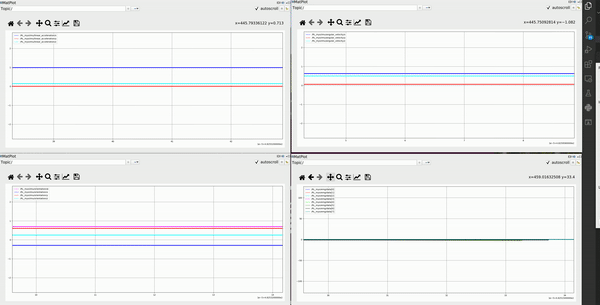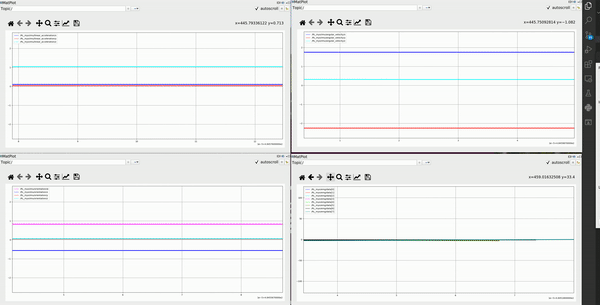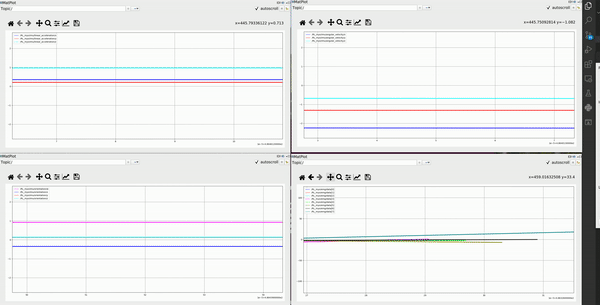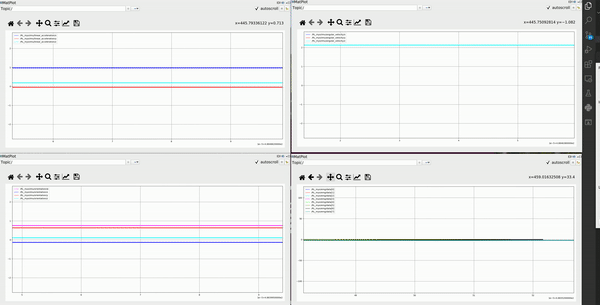
-
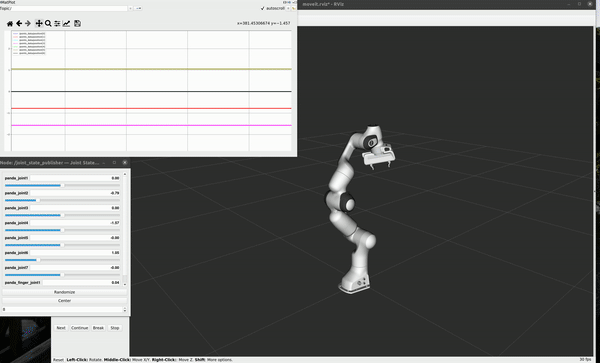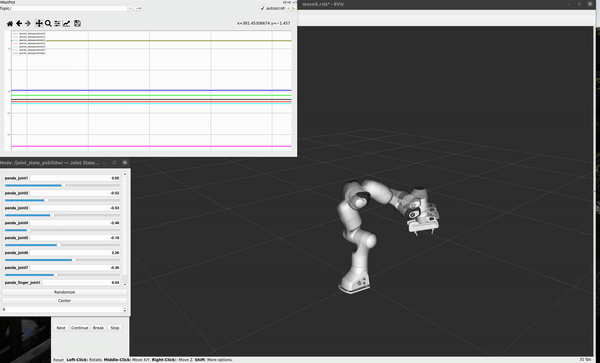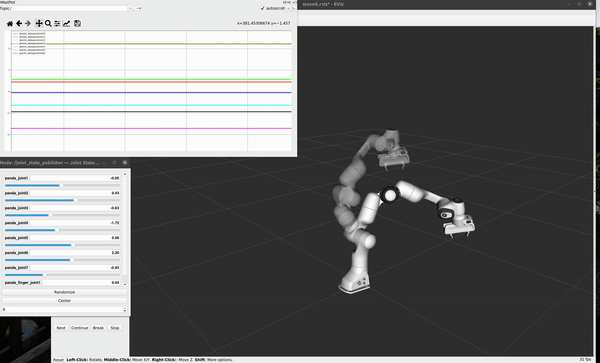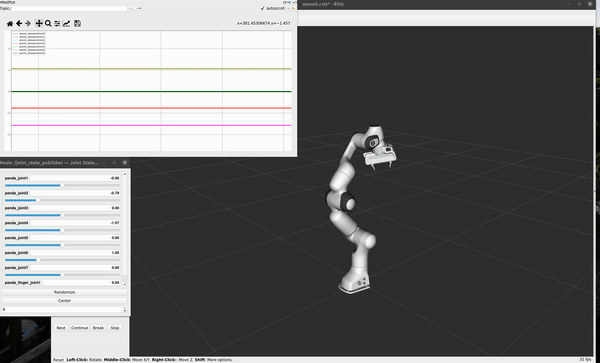
Raw Robot Data
-
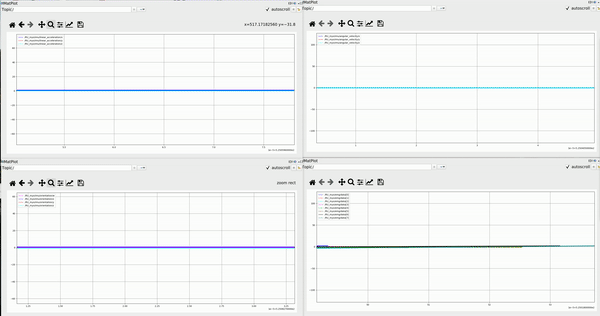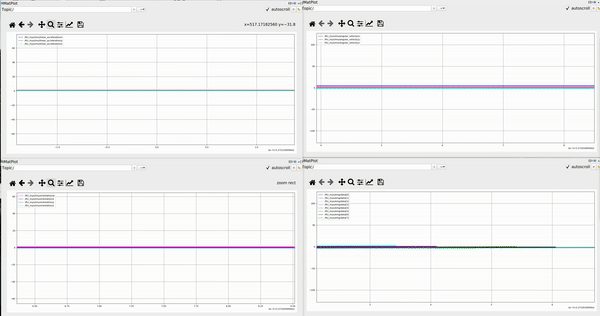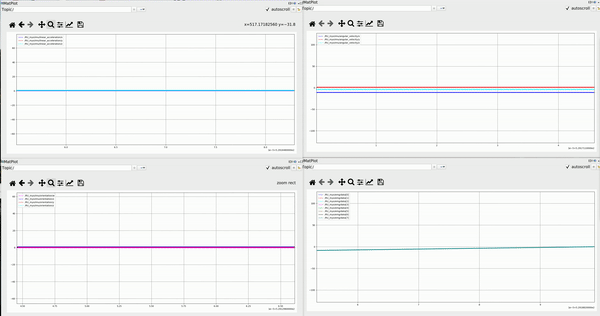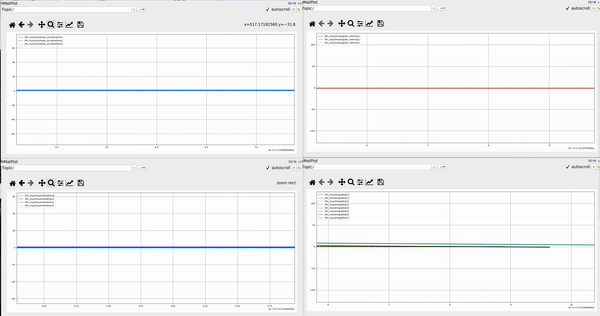
Positions of 7 joints monitored at 10 Hz during specific motion
-
Velocities of 7 joints calculated from monitored position during specific motion
-
The collecting demo for one repeat of task 2 shows following:
-

Data processing
-
Post Processing
-
signal post-processing for both raw data collected from human and robot.
-
For human: downsampling (decimate) both EMG/IMU to the rate at 10 Hz
-
For robot: downsampling (decimate) one segment of datapoints to 8 points, add 2 static points at the end of each segment. Integrate 4 segments into single sequence.
-
Concatenate 10 repeats for both human and robot data, and then align them to obtain the original dataset.
-
-
Data augmentation
-
Using sklearn.preprocessing.MinMaxScaler to normailize the original data to the range at [-1, 1]
-
Horizontally concatenate all data points at current time (at t) with them at previous time (at t -1)
-
Split dataset into training set and testing set at ratio of 80:20
-
Mask all robot data in training set with value -2 to obtain the case 2 dataset; mask all original data at t in training set with value -2 to obtain case 3 dataset
-
Vertically concatenate original data with case 2 and case 3 data to obtain the final augmented training set
-
Model training
-
Multimodal variational autoencoder (mVAE):
-
A variational autoencoder (VAE) is a latent variable generative model. It consists of an encoder that maps the input data x into a latent representation z = encoder(x), and of a decoder that reconstructs the input from the latent code, that is x = decoder(z). The information bottleneck given by mapping of the input into a lower-dimensional latent space yields to a loss of information, measured by evidence lower bound (ELBO):
- Where KL[p, q] is the Kullback–Leibler divergence between distributions p and q, while λ and β are parameters balancing the terms in the ELBO. The ELBO is then optimized via stochastic gradient descent, using the reparameterization trick to estimate the gradient. In practice, since the main focus of this study is the reconstruction capability of the model, we chose β = 0, and only consider the reconstruction loss to train our architecture, noticing improvements in the reconstruction performance obtained.
-
This project extends standard VAE to multimodal data, the multimodal variational autoencoder (mVAE) is formed of 6 encoders and decoders, one for each sensory modality. Each encoder and decoder is an independent neural network, not sharing weights with other modalities’ networks. The latent representation is however shared: each encoder maps its input (one sensory modality) into the shared code z. The network architecture is depicted below:
-
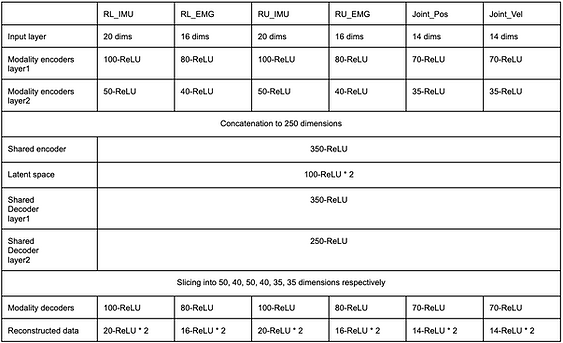
-
Augmentation on training dataset:
-
The biggest strategy of training this model is apply data augmentation (described above) on the original dataset used for training:
- The original dataset is time series data that collected and aligned from human and robot motion
-
By concatenating data from time t and t - 1, the temporal relationship between different modalities
-
By masking partial data, the network is trained on both complete and partial samples that can be required to reconstruct the missing modalities given some of them. The training dataset follows the below structure to enable the network to perform predictions and reconstruction in multiple conditions of missing data:
-
-
Training the model:
-
Training parameters:
-
learning rate: 0.00005
-
batch size: 1000
-
optimizer: Adam
-
training epochs: 80000
-
-
Training results:
-
The loss consist two terms:
-
The reconstruction loss (the negative log probability of the input under the reconstructed Bernoulli distribution induced by the decoder in the data space). This can be interpreted as the number of "nats" required for reconstructing the input when the activation in latent is given.
-
The latent loss, which is defined as the Kullback Leibler divergence between the distribution in latent space induced by the encoder on the data and some prior. This acts as a kind of regularizer. This can be interpreted as the number of "nats" required for transmitting the the latent space distribution given the prior.
-
-
The average reconstruction loss and average latent loss over one batch (size=1000) during 80000 epochs are shown below.
-
From the left plot, the average reconstruction loss dramatically dropped from 14 to 2 during first 10000 epochs, and even reached negative value after 25000 epochs. The loss fluctuated from -1 to 4 after 20000 epochs with standard deviation of 1.98. The stochastically sampling of each batch could contribute the fluctuation.
-
From right plot, the average latent loss approached 700, which is significantly large comparing to reconstruction loss. However, this loss will have to multiply a coefficient "alpha", which approached zero as epochs increasing. Therefore, the overall loss achieves a good result.
-
-


Testing Result
-
Performance Testing: (metric: MSE)
-
Test 1: predict (reconstruct) robot data from complete original data:
-
Test 2: predict (reconstruct) robot data from human data only:
-
Test 3: predict (reconstruct) all data at t from all data at t- 1 only:
-
Test 4: predict (reconstruct) future robot data (at t + 1) from human data only:
-
Feed the huamn data only, to predict (reconstruct) the complete data
-
Feed the data at t only from the previous reconstructed data again, now predict the future robot data (at t + 1)
-
-
Result for each test and plots for test 4 (comparing the original pos/vel at t with predicted pos/vel at t + 1) shows below:
-


-
Discussion
-
The ultimate objective is to predict the future robot motion by monitoring the current human motion, which is the depicted in the test 4. However, by conducting the previous three test, it is clear to see the performance on each portion.
-
Test 1 and Test 2 demonstrate that the prediction error of robot data is tiny from complete data, and the error increases when feed human data only but it still achieves a great performance on position prediction.
-
Test 3 shows when predicting data at time t (both human data and robot data) from data at time t -1, the performance is similar comparing to Test 1. This could be the reason that only one datapoint shift does not contribute significant changes in state with 10Hz. The project could apply more time shift in future to further explore the prediction performance.
-
Test 4 basically utilizes the functions in test 2 and test 3, including two stages of reconstruction. The initial fed dataset contains only human data, then use the reconstructed data at time t only to feed as data at time t - 1 in the secondary dataset. By predicting the data at time t for the secondary dataset, we can obtain the future data (at time t + 1) in terms of the initial dataset. From the above plots, it can be found that the prediction for positions generally matches the ground truth positions. The prediction for velocities matched the trend of ground truth values as well, although some dramatic points in joint 1, 2, 4 were not caught by this model. Specifically, this missing points are either -1 or 1, which are the boundaries of our data.
-
Conclusion and future work
This project takes inspiration from the paper Multimodal representation models for prediction and control from partial information[1]. Based on the testing result, it can be concluded that our model is able to predict or reconstructed the future robot state by given current human state. For the model training, exploration in tuning network architecture is worthing, since the current one is just an analogy to the ratio of the model in paper. A better strategy on usage of latent loss could be a next approach to improve the prediction performance. Additionally, the model deployment on ROS to enable a live control of robot arm will be the significant stage in future. This implementation should carefully deal with the signal processing in real time, including normalization and frequency reduction. If the kinematic works well, the dynamics of robot arm, like torque, gripper force could be added as new modalities to the network.
References
[1]Zambelli, Martina, et al. “Multimodal Representation Models for Prediction and Control from Partial Information.” Robotics and Autonomous Systems, vol. 123, 2020, p. 103312., https://doi.org/10.1016/j.robot.2019.103312.